By
Unit Zero Labs
Research
•
8
min read

What is the usefulness of a chat agent in the hands of a human? The answer to this question is a lot more complicated than you might think. For now, it is mostly useful as a next-gen wikipedia or google in your pocket that you can talk to and get somewhat quality answers from without providing it much context. This seems to be the general consensus among non-techno anarchists, wherein the promise of AI is underdelivered. This is a serious misconception, and does a disservice to the brilliance of the mechanics behind these systems and what they are capable of.
The current state-of-the-art open source large language models are impressive. Claude-3-Opus achieves over 95% on reasoning benchmarks and over 80% on coding benchmarks. This is the first LLM to achieve over 80% on coding tasks. GPT-4, which many would agree is the most popular and widely used state-of-the-art model, could only achieve 67% on python coding benchmarks. GPT-3.5 scores a paltry 48%.
It is easy to recognize how quickly the state-of-the-art is advancing in this space; newer models are making gigantic leaps in reasoning, logic, math, coding, and other tasks. Companies like Mistral and X (formerly Twitter) are making enormous and complex models like Mixtral-8x7B and Grok publicly available, which greatly enhances the development community’s ability to make contributions to the novel tech.
The secret recipe for building better models is simply in the sheer volume of data the model is trained on. In the chart below, from Llama-2 in 2023 to Gemma in 2024, the number of pre-training tokens used to train open source LLMs had tripled. Less than two months later, Databricks announces the release of their open source model called DBRX which doubled that number again.
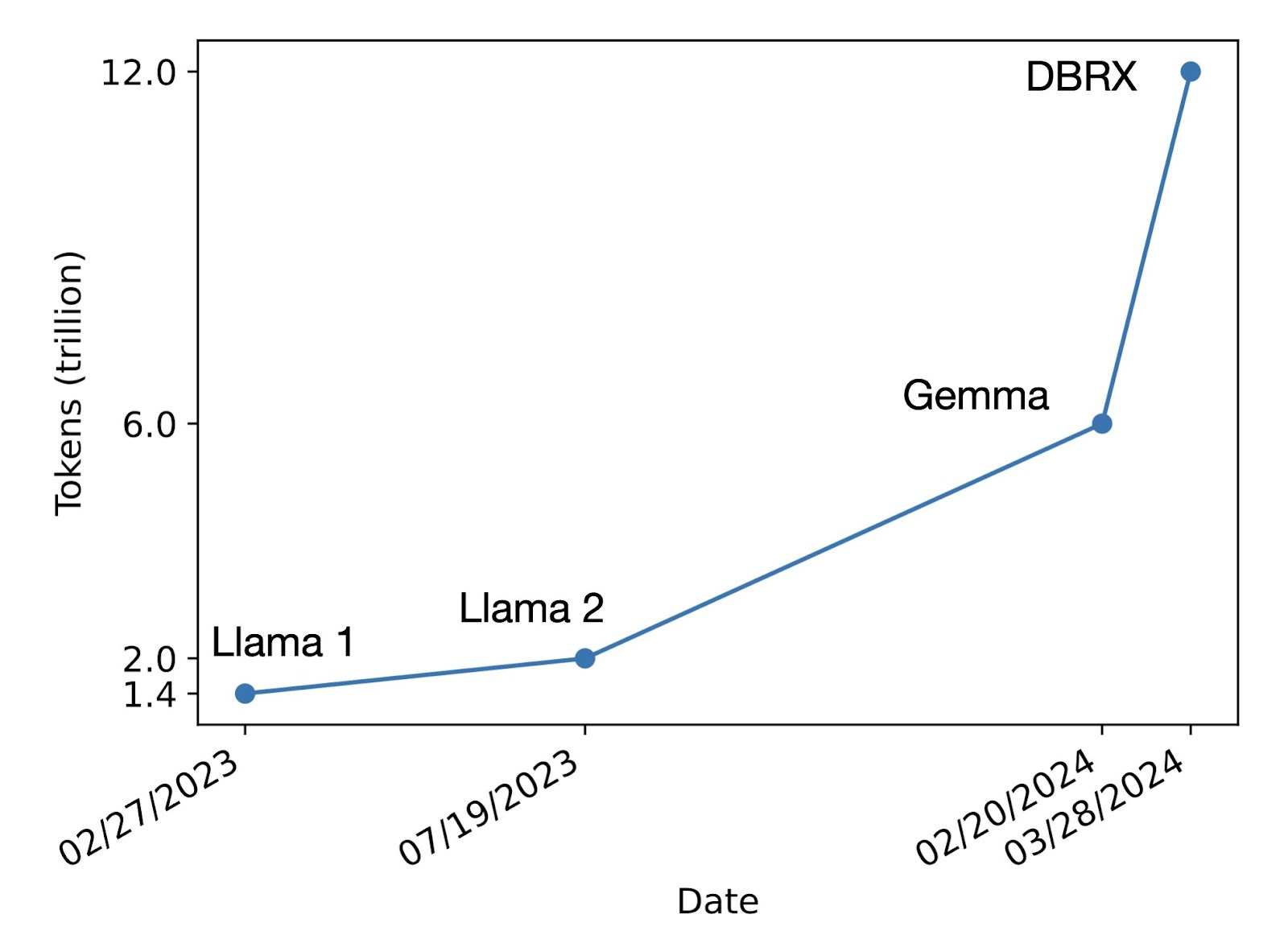
How are we so easily able to double the amount of tokens a model is trained on? More GPUs of course. More chips running training algorithms for longer periods of time. Which is extremely expensive, but worth it to inch us closer toward the goal of general intelligence. Nobody is concerned about the mounting costs to scale these model builds; rather the focus is on ensuring Nvidia can build enough chips to support this growth. And the impacts to the bottom line are notable: OpenAI already does $1B in revenue annually. Nvidia has grown faster than any stock in history. LLM products are in their infancy, yet the demand for the next best product is insatiable. And everyone is split on the topic of open source.
There are those like Anthropic and OpenAI, arming the best and brightest researchers with huge funding to build closed source models and position their businesses to profit off of users committing to pay for their chat bots in a SaaS setting. Then, there are those like X (formerly Twitter), Mistral (a French AI startup that Microsoft has invested in), who use their funding to empower the best and brightest minds to work in the open, publicly releasing their next generation models to help advance the science as a whole. While Anthropic and OpenAI still maintain the most powerful models in the market, and thus the majority of market share, other players in the space are encroaching fast while publicizing all of their research. This could loosen the grip on the market that the closed source companies have gained so quickly.
A result of this is that it increasingly seems like using the best models available will become cheaper as better models become more freely available. Anyone with the raw computing power required to download Grok or Mixtral-8x7B can run inference locally (i.e. ask an LLM questions without accessing the internet). While the computing power required for that may seem prohibitive now, we obviously know where that trend is headed. Even now you can download Meta’s latest open source Llama model containing 7 billion parameters on a Macbook with 16GB memory. That is a rather large model to download locally, but pretty much anyone with a Macbook or PC made after 2021 could do it.
If you were to work with a Llama2-7B model locally as described above, you might ask it a question in your initial prompt and achieve less than desirable results. The response is unsatisfactory; what is the cause for the hype if this chat bot cannot get my simple question right? What is often misunderstood about these chat agents is that they are generally okay any question right off the bat, but they are significantly enhanced with a little context and direction.
The latest models released by the likes of OpenAI and Anthropic are what's known as ‘zero-shot’ models. By definition, this means they are designed to perform tasks without requiring any additional training or fine-tuning. However, even these advanced models can benefit greatly from well-crafted prompts that provide context and guide their responses.
Imagine a scenario as described above where you have access to a local instance of a powerful language model (like Llama2-7B), and its responses to your questions are of low quality. This is where the art of prompt engineering comes into play. By carefully crafting your prompts, you can unlock the true potential of these models and engage in more meaningful and targeted interactions. For example, let's say you want to explore the philosophical implications of artificial intelligence. Instead of simply asking, "What are the philosophical implications of AI?" you could provide a more nuanced prompt:
"Assume the role of a renowned philosopher with expertise in the ethics of artificial intelligence. Consider the rapid advancements in AI, particularly in the realm of large language models like GPT-4 and Llama2-7B. Analyze the potential philosophical implications of these technologies, taking into account issues such as consciousness, agency, and the nature of intelligence. Provide a thoughtful and well-reasoned response that explores both the benefits and risks associated with the development of increasingly sophisticated AI systems."
By framing your prompt in this manner, you are essentially priming the model to adopt a specific persona, focus on relevant topics, and deliver a more comprehensive and insightful response. The model can draw upon its vast knowledge base to generate a response that is tailored to your specific query, rather than providing a generic or surface-level answer.
As more powerful models become accessible to a wider audience, the ability to craft effective prompts will become increasingly valuable. This is mostly a topic for another discussion, however it's true that those who master the art of prompt engineering will harness more potential from the models, engaging in deeper, more meaningful conversations that push the boundaries of what is possible with AI-assisted exploration and discovery.
Indeed, much of the latest research on LLMs is regarding ‘Chain of Thought” reasoning, which is legitimately adding a byline to your prompt telling the chat agent to “think step by step”. The paper that introduces this concept states that chain of thought, “in principle, allows models to decompose multi-step problems into intermediate steps, which means that additional computation can be allocated to problems that require more reasoning steps”. The paper goes on to note that adding chain of thought prompts to older models like Google’s PaLM and GPT-3 brings them within inches of state-of-the-art.
In this sense, the right prompt can indeed allow you to "speak to God" – or at least to a highly knowledgeable and insightful entity that can help you navigate complex ideas and uncover new perspectives. If you believe that these models will continue advancing toward achieving general intelligence (we do) then speaking to some higher entity is frankly a matter of asking the right questions.
It is as philosophical as it sounds; models will get smarter, more weights will be released publicly, and conversations with agents become significantly better. More enlightened. Communicating with a 200+ IQ organism, be it digital or organic, is only a matter of time.
Anywhere there is demand for a service wherein the supply of that service can be provided by a distribution of similarly incentivized peers, then there is a use-case for a blockchain.
This is a principle that we think guides how AI-driven agents might proliferate in the near future. As the demand for personalized, intelligent assistants grows across various domains, from healthcare and education to finance and entertainment, the development and deployment of these agents could be facilitated by a decentralized protocol to align incentives.
Imagine developers and data providers are rewarded for contributing their resources and expertise to the creation and refinement of AI agents, as discussed in the second article of this series. By providing computing power and skills, contributors earn tokens for collaboration on training and fine-tuning large language models, adapting them to specific tasks and user preferences.
The protocol’s permissioned access and token-based reward system can enable a self-sustaining economy, encouraging participants to continuously improve the quality and diversity of available agents. As more users engage with the network, the pool of intelligent assistants could expand, catering to an ever-growing range of needs and requirements.
But an important question remains - why are we so convinced a blockchain could serve a purpose here? Surely, OpenAI and Anthropic are not considering tokenizing their enormously lucrative chat bots to share the profits in the name of “decentralization” (although, this is sort of exactly why OpenAI was named as such). Maintaining control over the latest developments of these hyper advanced models will boost both their bottom line as well as humanity’s chances of achieving artificial general intelligence. Would someone in their basement eventually be able to figure it out? Perhaps, but with billions in the war chest to be used for renting GPU space, OpenAI and Anthropic are most likely to figure it out first.
And this is great, considering humanity will benefit from the achievement. But we think that this should be viewed more closely from an anti-trust perspective. Consider the monopoly power gained for the corporation that achieves AGI first. The implications would be dramatic; The winning company would take a lot of market share from other providers, which gives more pricing power. They would also maintain full control and influence over the tones and attitude of the resulting model. This might be OK if we trust OpenAI, just like we trust Apple with every shred of data we have ever generated digitally. Do we trust OpenAI? If distrust for Siri and Alexa is already present, what makes you think society would willingly integrate a smarter version of them into everything they do?
Protocol decentrality can ensure that no single entity is able to monopolize the development or access to AI agents. Instead, users would have the freedom to choose the agents that best suit their needs, paying tokens to interact with the desired inference engines. This creates a fair and efficient marketplace, where the value of an agent is determined by its utility and performance. In this hypothetical marketplace, it seems natural that decentralized and community-sourced agents would proliferate, much like how decentralized financial services have proliferated among traditional finance with cheaper and faster methods of settlement. The total DeFi market cap excluding BTC and ETH is around $750B, up from $50B in 2019. The math speaks for itself.
If you’ve gleaned anything from this piece of the series, it should be this: we think a decentralized model for LLM agents will prevail not because its more fair and we need it as a society, but because its simply a more efficient marketplace for them. Training models requires compute costs, and these costs can be distributed among participants earning tokens for their labor. And as LLMs continue to advance at a breakneck pace, the potential for transformative applications and profound conversations grows ever closer. Centralized entities currently lead the charge, but the emergence of open sourced and decentralized alternatives may soon reshape the landscape, offering a more accessible and equitable future for AI. Though challenges remain, one thing is clear: the era of artificial general intelligence is no longer a distant dream, but an approaching reality that will redefine our relationship with technology.
For inquiries and further information, please contact:
Unit Zero Labs





